Data Pipeline é um conjunto de processos automatizados para processar dados de forma eficiente e consistente. É amplamente utilizado em cenários onde dados brutos precisam ser extraídos, transformados e estruturados para serem consumidos por aplicações, dashboards, ferramentas de BI, relatórios ou outros meios de análises de dados.
Neste artigo, vamos criar um Data Pipeline simples utilizando AWS Lambda e Amazon S3. A ideia é processar logs brutos de uma aplicação local, extrair dados relevantes e armazená-los em um bucket do S3 como JSON. O resultado será uma automação para processamento de logs diários que você pode usar como modelo para construir coisas bem mais robustas! Bora lá?
Pré-requisitos
- Python:
- Ter o Python instalado em sua máquina.
- Conhecimento básico de Python, mas caso não tenha, não se preocupe, pois os scripts serão simples e eu estarei explicando o que eles fazem.😎
- Conta AWS:
- Se você ainda não tem uma conta, crie uma aqui.
- É importante ressaltar que os serviços AWS são cobrados por uso, mas aqui utilizaremos apenas serviços elegíveis para o nível gratuito, que oferece limites generosos e suficientes para o que precisamos.
- Se você quiser utilizar esses serviços em escala maior, recomendo monitorar o consumo para evitar surpresas. A AWS oferece ferramentas, como alarmes de faturamento, que podem ajudá-lo a acompanhar o uso de forma fácil.
- Usuário IAM:
- Estando logado no console AWS, crie um usuário IAM com as permissões necessárias para utilizar S3 e Lambda.
- Procure por IAM, clique em Usuários e depois em Criar usuário.
- Insira
data-pipeline-usercomo nome do usuário e clique em Próximo. - Selecione Anexar políticas diretamente, procure por
AmazonS3FullAccesseAWSLambda_FullAccess, marque o checkbox de cada uma e clique em Próximo. - Após revisar a configuração, clique em Criar usuário.
- Clique no usuário que acabou de criar e depois em Criar chave de acesso.
- Selecione a opção Código local e clique em Próximo.
- Insira uma descrição (opcional) para a chave e depois clique em Criar chave de acesso.
- Por fim, você verá seu Access Key ID e Secret Access Key, então guarde-os em local seguro, pois esta é a única vez que será possível visualizar o Secret Access Key. Caso o perca, terá que criar outra chave.
- Configurar variáveis de ambiente:
- Configure no seu sistema operacional as seguintes variáveis de ambiente com as chaves do seu usuário IAM e a região padrão:
- AWS_ACCESS_KEY_ID=
seu-access-key-id - AWS_SECRET_ACCESS_KEY=
seu-secret-access-key - AWS_DEFAULT_REGION=
us-east-1
- AWS_ACCESS_KEY_ID=
- Configure no seu sistema operacional as seguintes variáveis de ambiente com as chaves do seu usuário IAM e a região padrão:
Como Vai Funcionar o Data Pipeline?
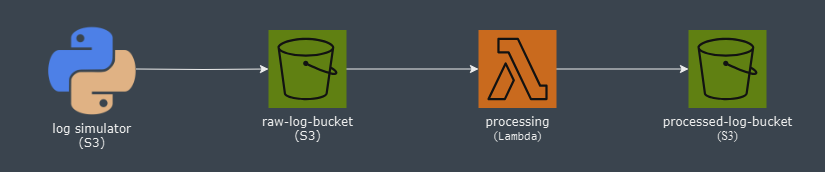
Vamos dividir o fluxo em duas etapas:
- Geração e upload de logs:
- Criaremos uma aplicaçao Python simples que irá gerar logs brutos simulando acessos às páginas de um e-commerce, registrando data e hora, nome da página, status e tempo de resposta.
- Todos os logs do dia serão gravados em um arquivo de texto plano, cujo nome terá a data do arquivo como sufixo.
- Diariamente, após a meia noite, a aplicação enviará o arquivo de logs do dia anterior para um bucket chamado
data-pipeline-raw-log-bucket.
- Processamento dos logs:
- No ambiente da AWS, uma função Lambda será acionada automaticamente sempre que um novo arquivo de logs chegar no bucket. Ela processará o arquivo extraindo dele os dados relevantes e estruturando-os como JSON.
- O arquivo JSON resultante será salvo em outro bucket chamado
data-pipeline-processed-log-bucket, e assim estará pronto para consumo por outros serviços.
Diagrama simplificado do fluxo:
Criando os Buckets no S3
No console AWS, procure por S3 e clique em Criar Bucket. Vamos criar nossos dois buckets:
- Bucket para os arquivos de logs brutos:
- Nome:
data-pipeline-raw-log-bucket. - Região: A região selecionada na sua conta será usada no bucket, mas caso esteja diferente da que configurou em sua variável de ambiente (
us-east-1), você deve alterar clicando no nome da região logo ao lado do seu nome de usuário, no canto superior direito da tela. - Configurações: Deixe o padrão.
- Nome:
- Bucket para os arquivos processados:
- Nome:
data-pipeline-processed-log-bucket. - Siga o mesmo processo do anterior.
- Nome:
Criando Política de Permissões
Aqui vamos criar a política de permissões necessárias para que a Lambda possa ler e gravar arquivos nos buckets S3.
No console AWS procure por IAM, depois clique em Políticas e Criar política:
- Em Ações permitidas filtre por
GetObject, que é a permissão de leitura no bucket. - Em Recursos selecione Específico e depois Adicionar ARNs para tornar a política de permissões específica para os buckets que criamos.
- Resource bucket name:
data-pipeline-raw-log-bucket - Resource object name:
* - Resource ARN:
arn:aws:s3:::data-pipeline-raw-log-bucket/*
- Resource bucket name:
- Essa configuação irá permitir leitura de qualquer arquivo do bucket especificado.
- Agora clique em Adicionar mais permissões e repita o processo para o bucket
data-pipeline-processed-log-bucket, mas em Ações permitidas você deve escolherPutObject, para permitir gravação no bucket. - Clique em Próximo e você verá uma tela pra revisar a configuração e definir o nome da política, que pode ser
data-pipeline-buckets-permissions, e então clique em Criar política.
Simulando Logs com Python e Fazendo Upload para o S3
Criando o Projeto e Configurando o Ambiente
Estrutura do Projeto
Crie um diretório para o projeto que você pode chamar de data-pipeline-log-simulator. Siga criando a estrutura de pastas e arquivos, mas deixe-os vazios, por enquanto, pois criaremos o código na sequência.
data-pipeline-log-simulator/
├── logs/
├── src/
│ ├── aws/
│ │ └── s3_file_uploader.py
│ ├── config/
│ │ └── log_config.py
│ ├── schedule/
│ │ └── log_file_upload_scheduler.py
│ └── log_simulator.py
├── .gitignore
└── main.pyCriando o Ambiente Virtual
No Python, é possível criar um ambiente virtual para cada projeto para isolar as dependências do ambiente global ou de outros projetos, evitando conflitos e facilitando a reprodução em qualquer ambiente.
Para isso, abra um terminal dentro do projeto e execute o comando a seguir:
python -m venv venvPara ativar o ambiente, execute o comando abaixo no Windows:
venv\Scripts\activateSe estiver no Linux ou macOS, use este comando:
source venv/bin/activateInstalando Dependências
Para interação com o S3, vamos precisar da biblioteca boto3, que é a lib oficial da AWS. Precisamos também da biblioteca APScheduler para executar os envios de logs para o bucket em um horário agendado.
pip install boto3 APSchedulerCriando os Arquivos Básicos
Agora que temos o ambiente virtual e as dependências instaladas, vamos criar um arquivo para listar todas as dependências necessárias para o projeto funcionar em qualquer ambiente. Este arquivo será o requirements.txt e pode ser criado com o comando abaixo:
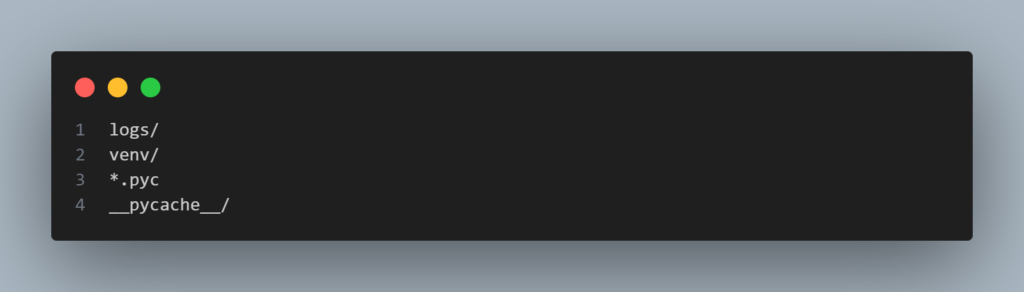
pip freeze > requirements.txtAgora precisamos criar no diretório raiz um arquivo .gitignore para listar tudo que não deve ser versionado pelo Git. Vamos ignorar o diretório de logs, o ambiente virtual e os arquivos que o Python gera automaticamente.
Criando os Scripts
Arquivo de configurações globais dos logs da aplicação: src/config/log_config.py
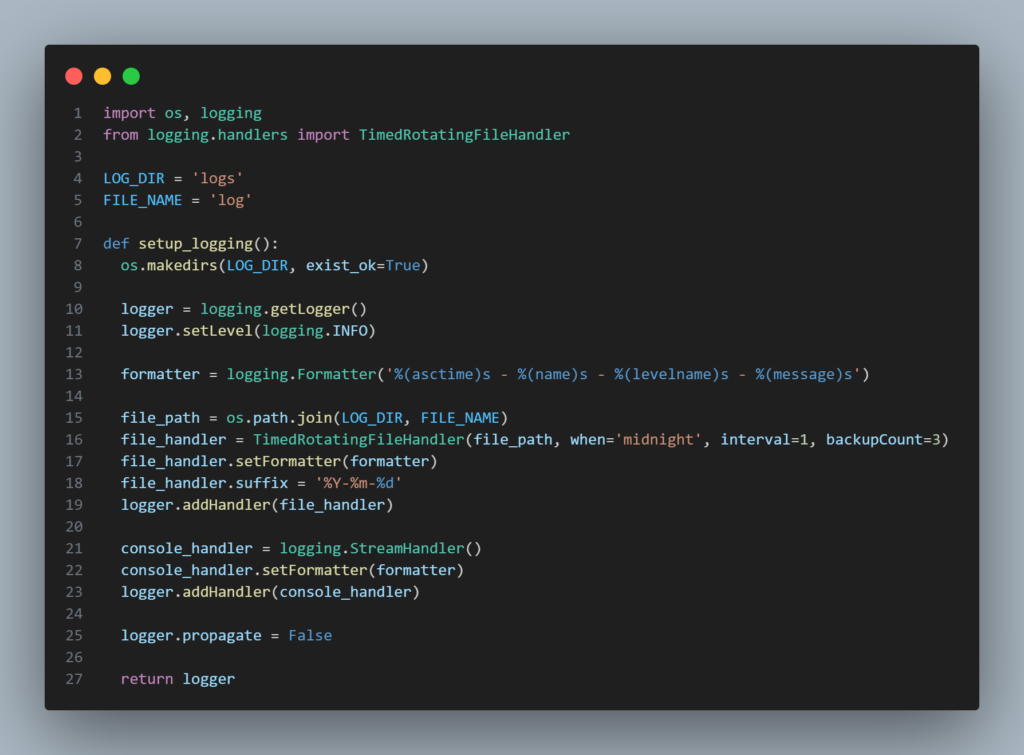
Este arquivo configura o sistema de logs para exibir no console e também salvar em arquivo, que é o que precisamos para enviar para o S3. Aqui estamos definindo que os logs serão gravados em arquivos diários que rotacionam à meia-noite, mantendo apenas os 3 mais recentes e adicionando a eles um sufixo de data no nome.
Script para simular logs de acessos às páginas de um e-commerce: src/log_simulator.py
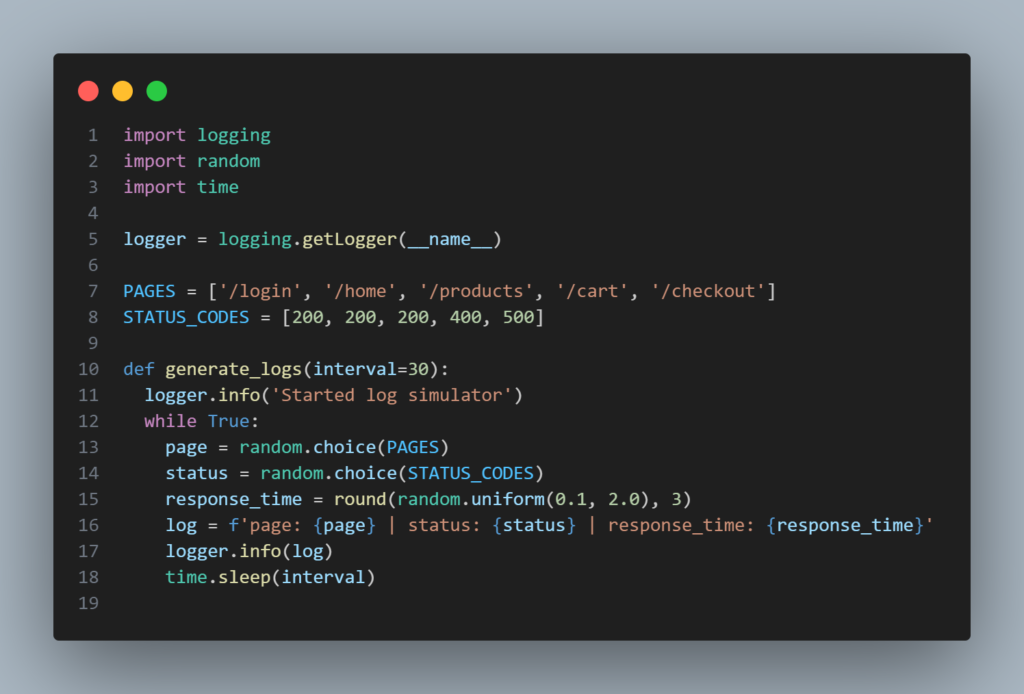
A função generate_logs() executa infinitamente com um intervalo definido (30 segundos por padrão), gerando logs e registrando-os com o logger que configuramos anteriormente. A cada execução é gerado um registro de log com valores aleatórios, que são eles a página acessada, o código de status HTTP e o tempo de resposta em segundos. O logger já está configurado para incluir data e hora de cada registro, então não precisamos incluir aqui também.
Script para enviar arquivos de logs para o bucket S3: src/aws/s3_file_uploader.py
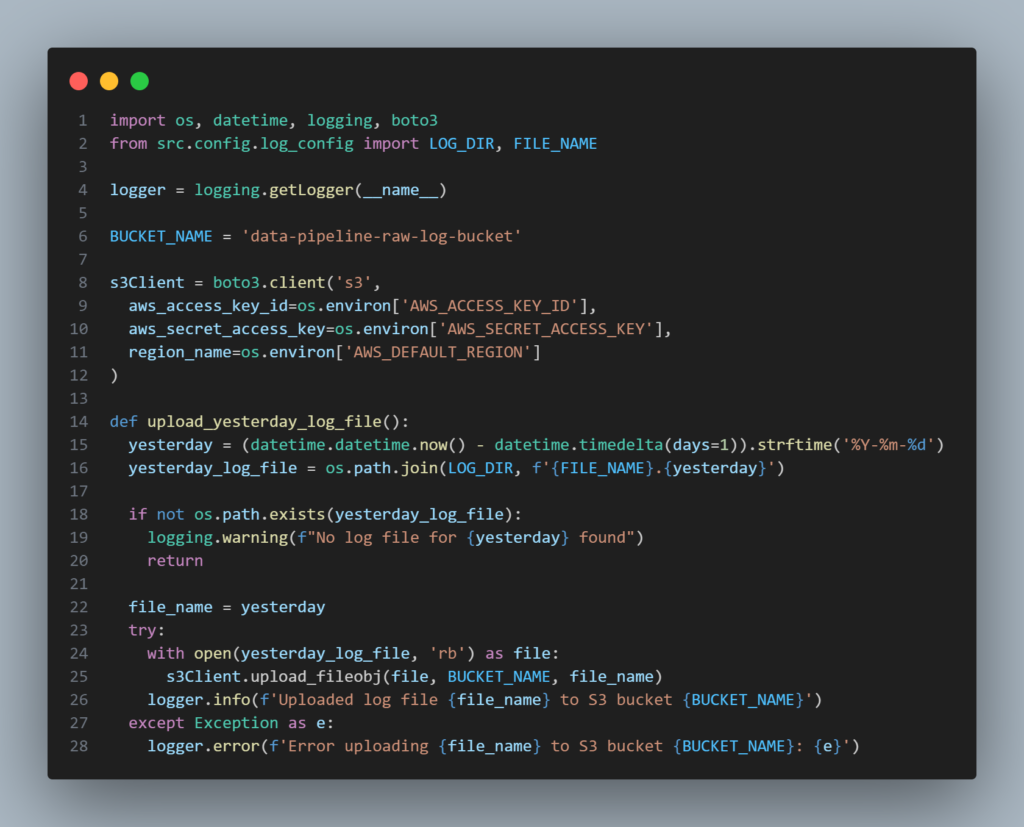
Aqui utilizamos o cliente boto3 para interagir com a AWS as chaves do usuário IAM definidas nas variáveis de ambiente. A função upload_yesterday_log_file() localiza o arquivo de logs do dia anterior pela data que está no nome do arquivo, como sufixo, e faz o upload para o bucket definido.
Script para executar a rotina diária de envio de arquivo de logs para o bucket: src/schedule/log_file_upload_scheduler.py
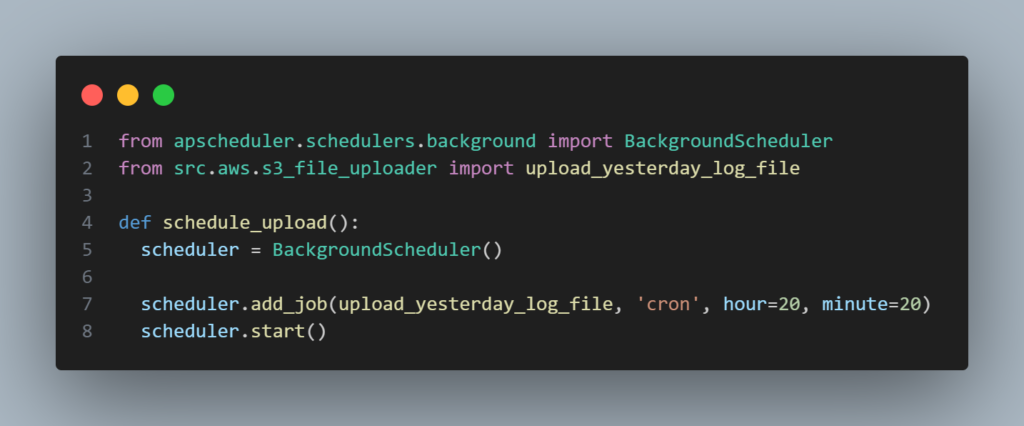
A função schedule_upload() utiliza a biblioteca APScheduler para iniciar um agendador e registrar uma tarefa que chama a função upload_yesterday_log_file todos os dias às 00:05. O horário está definido para 5 minutos após a meia-noite para garantir que o arquivo de logs do dia anterior já esteja disponível para envio.
Arquivo principal para iniciar a aplicação: main.py
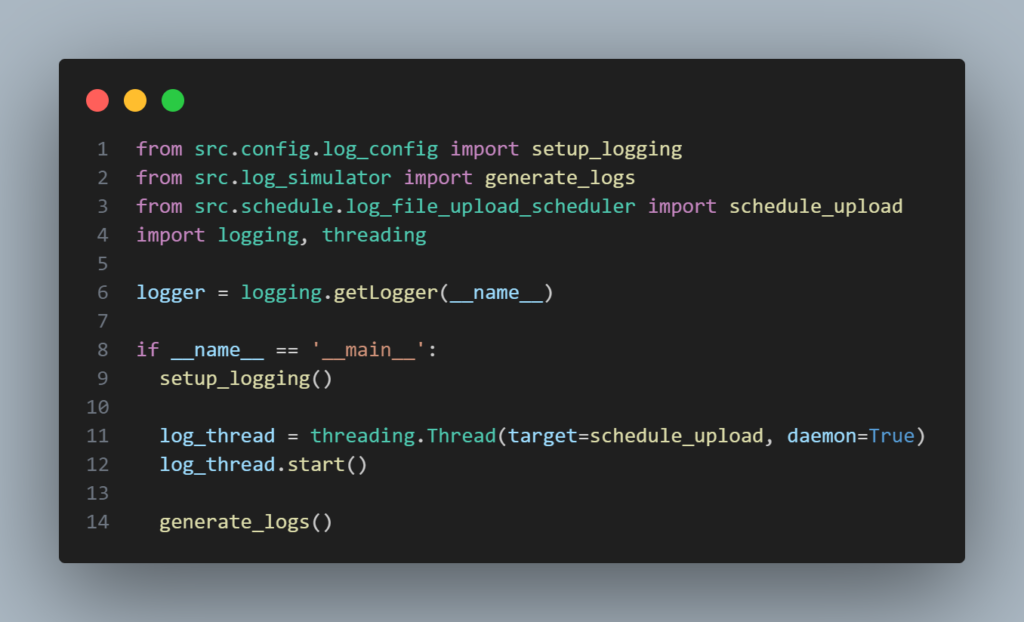
Este arquivo importa os módulos que criamos e os executa:
- Chama a função
setup_logging()para configurar o logger da aplicação. - Inicia o agendador de upload dos logs em uma thread separada que irá executar a função
schedule_uploadem segundo plano. - Chama a função
generate_logspara iniciar a simulação contínua de logs na thread princial da aplicação.
Criando e Configurando a Função Lambda na AWS
Agora vamos criar a nossa Lambda que será responsável por processar os arquivos. Será uma função simples escrita em Python, mas claro, rodando diretamente no ambiente da AWS, então é lá que vamos criá-la.
Criando a Função
No console AWS, procure por Lambda e clique em Criar Função. Escolha a opção Criar do zero e defina um nome, que pode ser data-pipeline-log-processor-lambda. Na opção Tempo de execução, você deve escolher a linguagem, que no nosso caso será Python 3.12, e clicar em Criar função.
Após criada, acesse a aba Código e você verá um editor de código com um arquivo lambda_function.py aberto. Escreva nele o código abaixo e clique na opção Deploy (Ctrl+Shift+U) para implantar no ambiente.
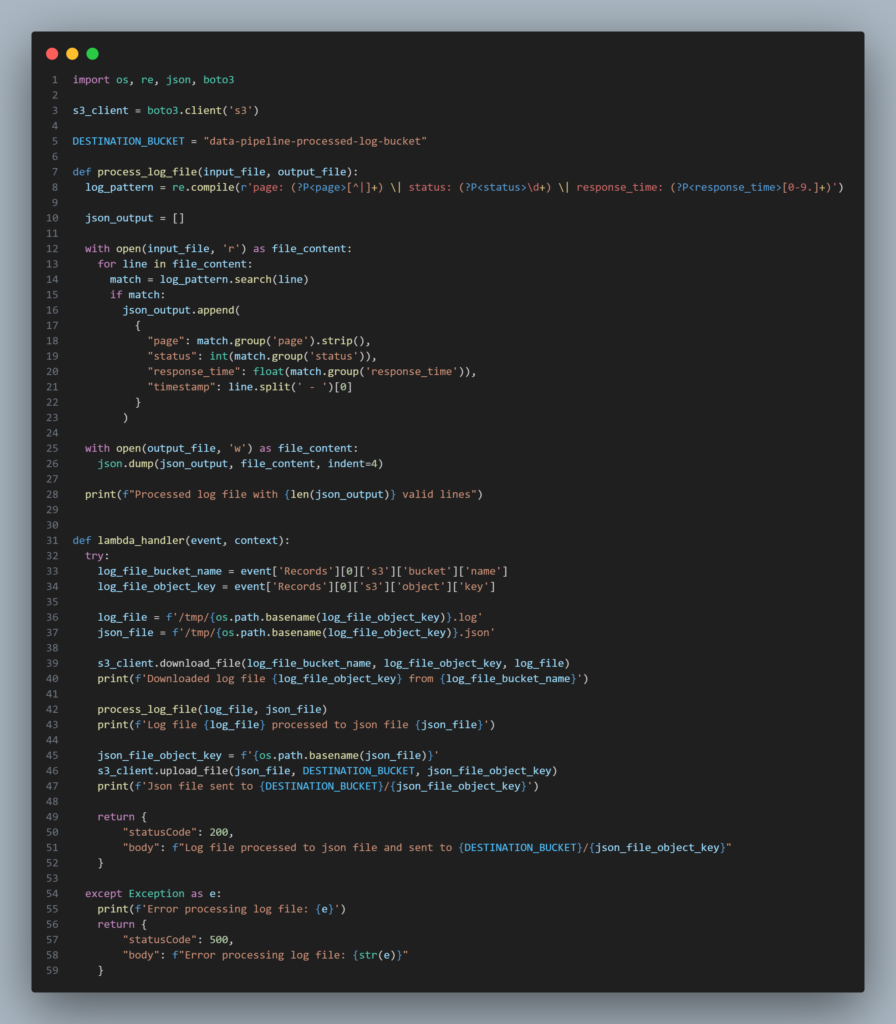
A função process_log_file lê um arquivo de entrada (input_file) e, para cada linha, extrai os dados relevantes (page, status e response_time) usando uma expressão regular. Com esses dados estrutura um objeto JSON e vai adicionando em um array. Ao final, escreve o conteúdo JSON no arquivo de saída (output_file).
A função lambda_handler é o ponto de entrada para execução da Lambda. Ela faz o download do arquivo de logs brutos do bucket S3 que acionou o evento, processa o arquivo utilizando a função process_log_file, que irá gerar o JSON, faz o upload do arquivo gerado para o bucket data-pipeline-processed-log-bucket e retorna o status da operação.
Configurando o Trigger (Gatilho) da Função
Agora vamos definir o gatilho para executar a Lambda automaticamente sempre que um novo arquivo chegar ao bucket data-pipeline-raw-log-bucket. Na Lambda, acesse a aba Configuração, depois Gatilhos e clique em Adicionar gatilho.
- Configuração do gatilho: S3
- Bucket:
data-pipeline-raw-log-bucket - Tipos de evento: Marque a opção
Todos os eventos de criação de objeto
Anexar a Política de Permissões à Lambda
Ainda na Lambda criada, acesse a aba Configuração e depois Permissões:
- Você verá uma função IAM que foi criada automaticamente e associada à Lambda, com um nome semelhante a
data-pipeline-log-processor-lambda-role-f8fsnf73. Clique nela para anexar a política de permissões que criamos no início. - Clique em Adicionar permissões e depois em Anexar políticas. Pesquise pelo nome da política que você criou (
data-pipeline-buckets-permissions), marque o checkbox e clique em Adicionar permissões.
Testando o Pipeline
Com tudo pronto, agora é hora da verdade! Será que vai? Cruze os dedos! 😁
No diretório do projeto Python, abra um terminal e execute o comando para executar a aplicação:
python main.pyVocê verá os logs aparecendo no intervalo definido, e no diretório /logs terá o primeiro arquivo que irá conter todos os registros até às 23h59, pois à meia-noite o arquivo rotaciona e a aplicação cria um novo.
Deixe a aplicação executando até o horário do schedule, mas caso não queira aguardar, você pode alterar o job para o horário desejado no arquivo log_file_upload_scheduler.py. O detalhe é que a regra de envio é para o arquivo do dia anterior, então você precisa ter no diretório /logs um arquivo com a data do dia anterior como sufixo (Ex.: log.2024-12-10). Nesse caso, apenas para o teste, você pode renomear o arquivo gerado, pois assim ele será encontrado e enviado quando o schedule rodar.
Após o envio, acesse o bucket no S3 para verificar o arquivo JSON processado. Caso não esteja lá, algo pode estar incorreto ou faltando, então será preciso revisar tudo que foi feito.😭
Em todo caso, você pode analisar os logs da Lambda no CloudWatch acessando a aba Monitor e clicando em Visualizar logs do CloudWatch. Se houve algum erro na execução da função, os logs ajudarão a identificar.
Conclusão
Neste artigo, vimos um exemplo prático de como integrar serviços da AWS para processar dados automaticamente de forma distribuída e escalável. Foi um processo bem extenso e desafiador, e se você é novo no assunto de AWS, pode ter achado complicado, mas continue explorando que eu garanto que logo estará afiado!
Fique à vontade para evoluir o projeto e incrementá-lo com mais serviços, pois as possibilidades são muitas. Você pode incluir mais etapas, como validação de dados, integração com serviços de análise como o QuickSight, persistir os dados em um banco de dados ou até mesmo enviar uma notificação de alerta para um tópico do SNS para ser consumido por alguma outra aplicação.
Se você gostou, compartilhe com outros desenvolvedores e comente no blog para me contar como foi sua experiência!🚀
Não deixe de conferir mais artigos sobre desenvolvimento de software acessando a categoria Desenvolvimento.



